Some empirical spaced-repetition results
I am a diligent flashcarder, and the tool I made uses a lot of randomness in its scheduling, for reasons I go into here.
I have well over 900,000 responses now, which is enough to let me do reasonable analysis of even fairly specific situations. So, for example: after a certain pattern of correct and incorrect answers, how sensitive is the correctness rate of the next response to the next interval?
Concretely: If I make a flashcard and my first three responses to it are (in this order) correct, incorrect, and correct, what is the relationship between the next time interval and my likelihood of getting the next (fourth) response correct?
Here's a chart:
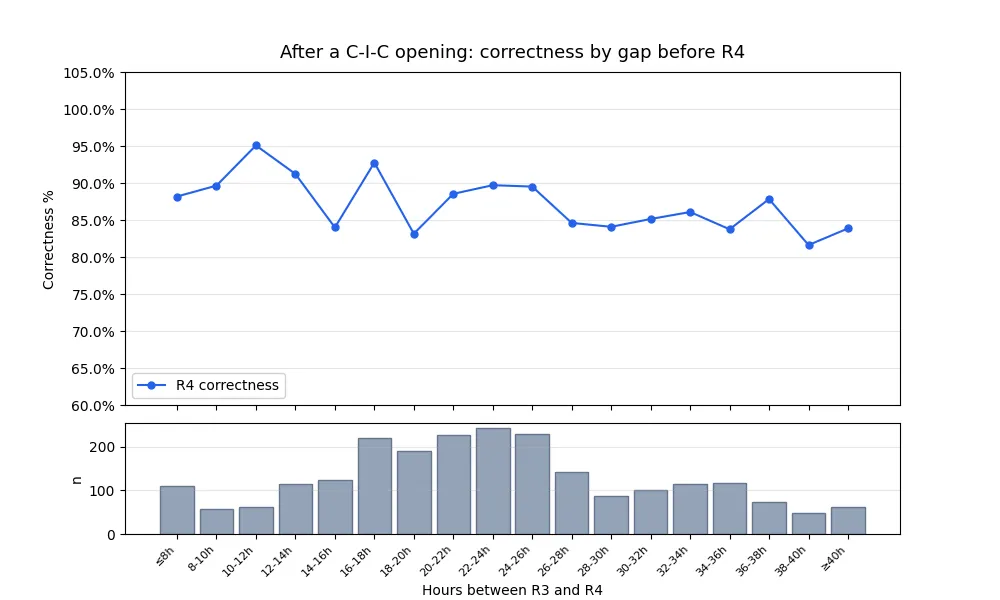
And here's the LOWESS-smoothed version:
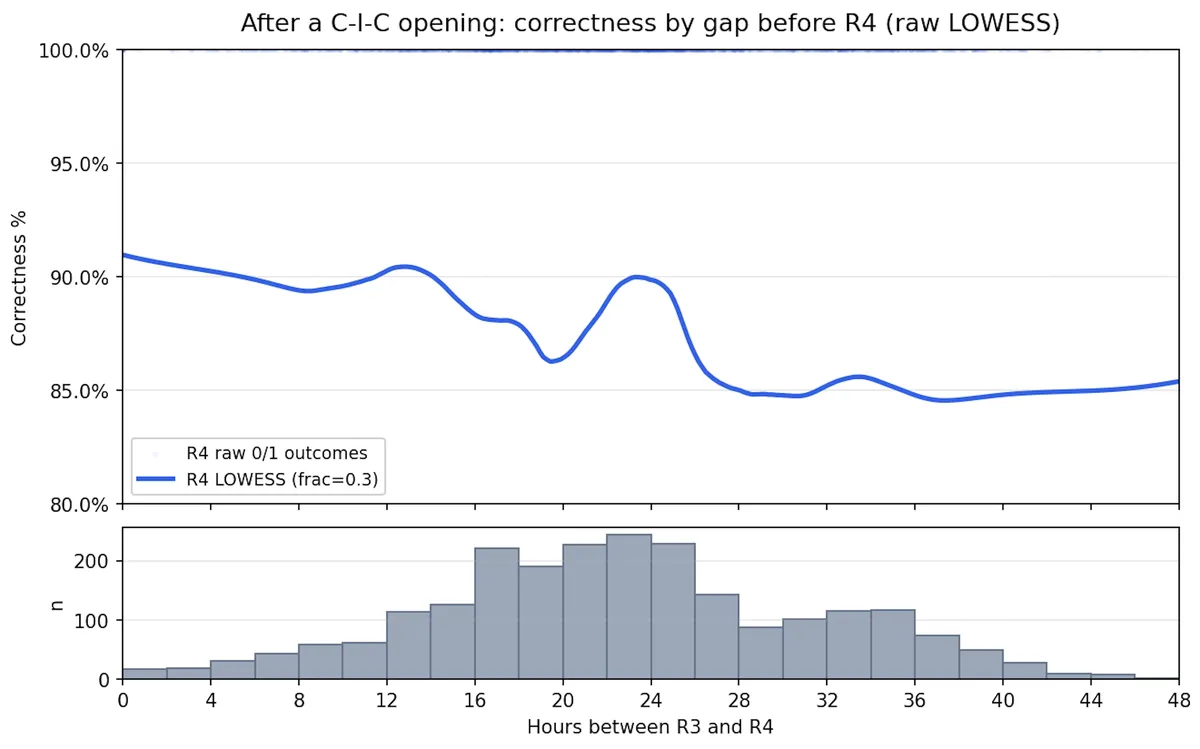
(In the former chart, <= 8 hours and >= 40 hours are bucketed together, so
A few notes:
- The very small intervals are mostly due to questions coming up randomly before they were scheduled to reappear. (My software injects random questions into study sessions, primarily to make it harder to guess the answer based on when I'm seeing the question but also to enable analyses like this.)
- The bump around 24 hours is interesting. My best guess is that this has something to do with consistency of environment: if I study a card on my lunch break or in bed in the morning, it's plausible that my performance will be better if I next see it in the same surroundings. Intervals very close to 24 hours are quite likely to keep surroundings constant.
- I'd call this a good data set, but not perfect. I've changed my scheduling algorithm over time, and it's possible that the questions I made while using one algorithm were systematically different than ones I made using another algorithm. I don't think it's plausible that effects like this are happening here at any meaningful magnitude, but it's worth noting.
- Those caveats aside, I suspect this data reflects a lot more precision and care than a lot of the memory data "in the wild." Some obvious reasons for this are that I'm quite honest and consistent about grading myself, and that I've kept this up for years. The less obvious reason is that I write narrowly focused, "atomic" flashcards that admit of well-defined grading in the first place. (If you've spent any time looking at publicly available flashcards, you know that a lot of them have prompts like "Why is RuBisCO important?" or "James Buchanan," and their answers are long and contain perhaps a dozen important facts. That makes it a lot harder to give a well-defined assessment to an answer.)
- The important question to be asking is: How should this change my scheduling algorithm? One way to think about this is: which intervals minimize the total effort to remember the card for the rest of my life (or, for concreteness and to sidestep morbid questions, for 20 years)? This is a hard question to answer empirically. The obvious brute-force approach would be to see how I do on questions where my first four responses are correct-incorrect-correct-correct ("CICC") and on CICI questions, then do an expected value calculation. But at least three obvious problems arise: the sample sizes get smaller and smaller; we don't know all that much about how spaced repetition works at decades-long scale; and, probably worst, the CICC question that would have been a CICI question had I waited an extra two hours is not the same as the average CICC question. So this is a tough problem!
- That said: it's a tough problem, but unless I'm mistaken I'm one of the likeliest people in the world to have the data and machinery to answer it, so I'm going to keep thinking about it.