The dynamic map labelling problem
Call the problem of displaying a user-defined, mutable subset of items on a map the dynamic map labelling1 problem. A few days ago I mentioned that this problem is (i) a lot harder than it first appears and (ii) a wonderful interview problem.
I still think it's a good interview question! The easy case, where the items are spread out enough that they don't conflict, tests something fundamental and elementary, but nontrivial (can you store data appropriately, accept input accurately, and construct something that depends on both?). The general case is not at all simple, and getting it right requires a range of important skills. There are many more details and sub-problems than one could discuss in an hour, yet the question isn't a black check that allows the candidate to discuss just anything.
I'd like to be able to pass my own interviews, so here are some notes on the question. For reference, here's the case2 (with Detroit on the East Coast, Green Bay an arm of Lake Winnipeg, and Atlanta in the Gulf of Mexico) that prompted me to think about this:
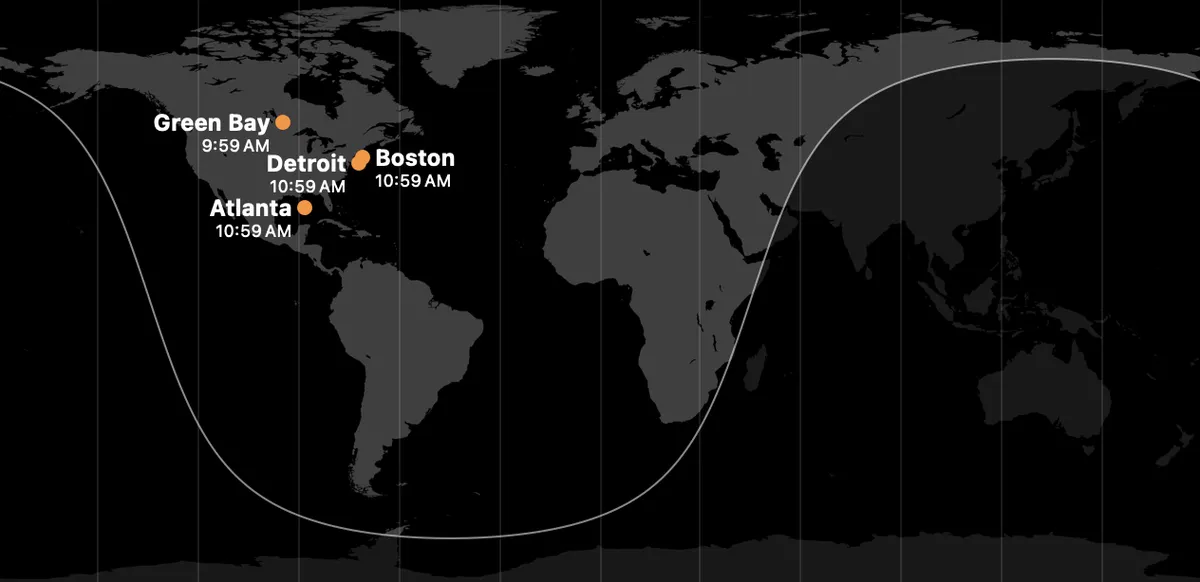
- The core difficulty is that locally good label placements can conflict with each other. So, before you know where to put the label for Boston, you probably need to know whether you also need to label New York, Providence, Cambridge, and/or other nearby cities.
- The structure of the best approach I know of is to (i) consider a bunch of candidate labelings, (ii) score them, and (iii) choose the labeling with the highest score. Scoring should, mostly or entirely, involve applying penalties for things like labels being too close together, dots being a certain distance away from their true locations,3 labels overlapping, and resorting to abbreviating a label.
- The best approach for generating candidate labelings is hard in theory but should be straightforward in practice. Most labels don't conflict, so (i) decomposing candidates into conflicting bundles4 and (ii) choosing a large set of reasonable candidates for any conflicting bundle should work fine, because "large" is relative to the size of the bundle, and even n! (or whatever) is fine if n is tiny. My first attempt would be to choose, for each conflicting set, the greedy configuration for each of the n! permutations of the elements of the set. (Think of a permutation as giving a priority order. Place the highest-priority item in the highest-scoring way, ignoring everything else. Then place the second-highest-priority item in a way that gives the best score for the two combined, and so on.)
- The best approach for scoring a configuration is, again, hard in theory but almost certainly tractable in practice. This is a fairly forgiving situation, because the set is small and and reasonable near-optimal solutions will usually be fine. In my experience, if (i) the situation is this forgiving, (ii) you put some thought into your initial scoring function, and (iii) you're willing to work through a good set of test cases, you often only need to revise your scoring function once (and can tweak it later as you wish).
There are many, many caveats here. So, for example, I've implicitly assumed that you can score a cluster without reference to other clusters. That assumption can fail: arguably, the first time you need an inset, a box around a label, or a line connecting a label to a dot, you impose a cognitive and aesthetic cost on the viewer, and subsequent uses of that device aren't as bad. But if you have penalties that are global in that sense, you can't calculate your scores both locally and accurately.
There are many other such complexities, but the ones that interest me most here live at the intersection of the algorithms and the user-facing design. This intersection always exists, but in this problem it's much more important than usual. Consider:
- How small a font is acceptable?
- What should the penalty be for resorting to an abbreviation?
- Can we use color to tell the user that a given dot corresponds to a given label?
- Should we crop the map down to some sub-region that includes all the labels bigger?
- Is the map interactive (in ways other than letting the user define the list of cities)? If so, will users be disoriented if small adjustments cause labels to jump around? (Do we need a penalty for "this label modifies what is currently being displayed"?)
- Is it most important for certain information to be intelligible immediately? How important is it for the map to show more information or otherwise bear scrutiny?
- Is it acceptable to have lines connecting labels and dots? (Are short lines part of the overall design language of the context already?)
I could go on. Considerations like this are why you can always tell when a labelled map on a Web site is has been generated with a general tool: with maps and labels, you hit the limits of a general solution quickly and obviously.5
As my experience in software has grown, and especially as I've started delegating so many narrow-scope software tasks to AI, I've become much more interested in this kind of design-heavy problem. These are domains where I'm most confident that humans with AI will be obviously and throughly outperforming AI alone for a long time to come.
It would be more informative, but also more annoying, to call it the "dotting-and-labelling problem." Arguably, this would be a less accurate name, because it suggests more strongly that dots and labels are all you need, and that might not be true. (What if you need boxes around the labels, lines connecting labels to dots, or color-coding?) Here as elsewhere, putting information in a name is dangerous. I'm happier just letting "labelling" refer to labelling in a broad sense, encompassing all that.↩
I wasn't trying to give adversarial input; these are the cities that I'd antecedently listed. I'm sure that the Clock app's algorithm works fine on many inputs (but even worse than this on others).↩
For me, the most irksome thing about the Clock app's treatment is that the dots are so far away from their correct locations. It so thoroughly violates the expected semantics of dot-on-a-map.↩
As usual, all roads lead to graph theory: you can do this by (i) finding all potentially conflicting pairs of labels, (ii) treating the labels as nodes of a graph, connecting if and only if they potentially conflict, and (iii) using any elementary traversal technique to find the graph's connected components. Techniques exist for doing (i) in sub-quadratic time, but quadratic time should be fine in this application. Defining "potentially conflicting" raises subtleties, because you only know what's potentially conflicting once you know the structure of your solution, but anything reasonable should work fine.↩
Here, for example, is the field map of the 2026 NAQT high school quizbowl championships. I am a big fan of OpenStreetMap and an even bigger fan of NAQT, and it's cool that this map exists: it's a whole lot better than nothing. But you can see why questions like "should we expand the map to include one team from Guam?" and "how important is it that the user be able to distinguish nearby points?" are irreducably domain-specific.↩